With Oktana, access 200+ nearshore and onshore resources to help you innovate with Salesforce and other technologies.
As a Salesforce Summit Partner, we work with each customer to build the right team to deliver ongoing managed services across complex, multi-cloud Salesforce implementations.
From a team of one to a team of many, our Staff Augmentation team can enable you to scale as needs arise, short-term or long-term, and any language, framework or technology.
87% of our work over the past 5 years has been within the High Tech sector, including HealthTech and FinTech. We understand the need to innovate quickly.





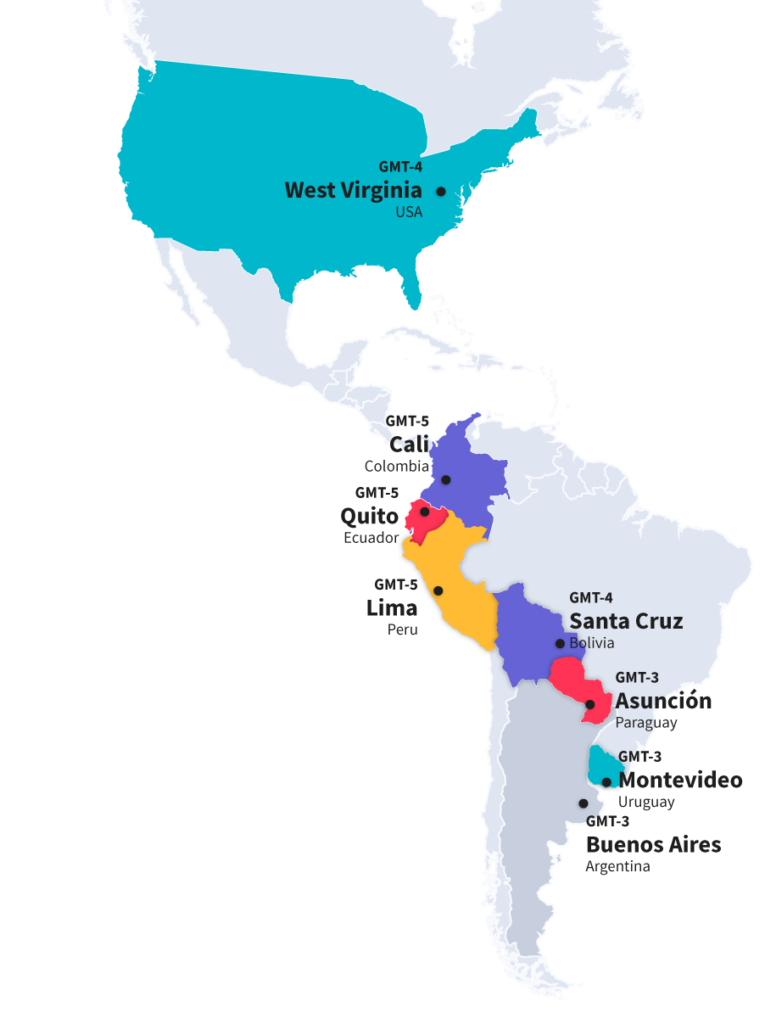
90% of our team is based in Latin America and bilingual with a generous overlap across shared American time zones.
We work as one team and enjoy sharing the uniqueness, and similarities, of each of our 8 countries.
Based on formal surveys through the Salesforce Partner Program, we are proud to share our 4.9/5 CSAT score based on expertise and delivery results.
![]() We are SOC 2 certified and maintain a rigorous compliance program to ensure data security. We code and implement with SDLC and Salesforce best practices in mind.
We are SOC 2 certified and maintain a rigorous compliance program to ensure data security. We code and implement with SDLC and Salesforce best practices in mind.
From billing on a Time & Materials basis to ensuring you approve your team’s PTO requests, we provide seamless flexibility. Our internal training team takes it one step further to enable your team to learn what they need to support your growth.
With 800+ Salesforce certifications, we can help you integrate the newest Salesforce technologies, including Einstein, Slack, Tableau, and MuleSoft.
By continuing to use this site, you agree to our cookie policy and privacy policy.