
What is DevOps?
The term “DevOps” combines the words developers and operations, which are typically two different teams in IT:
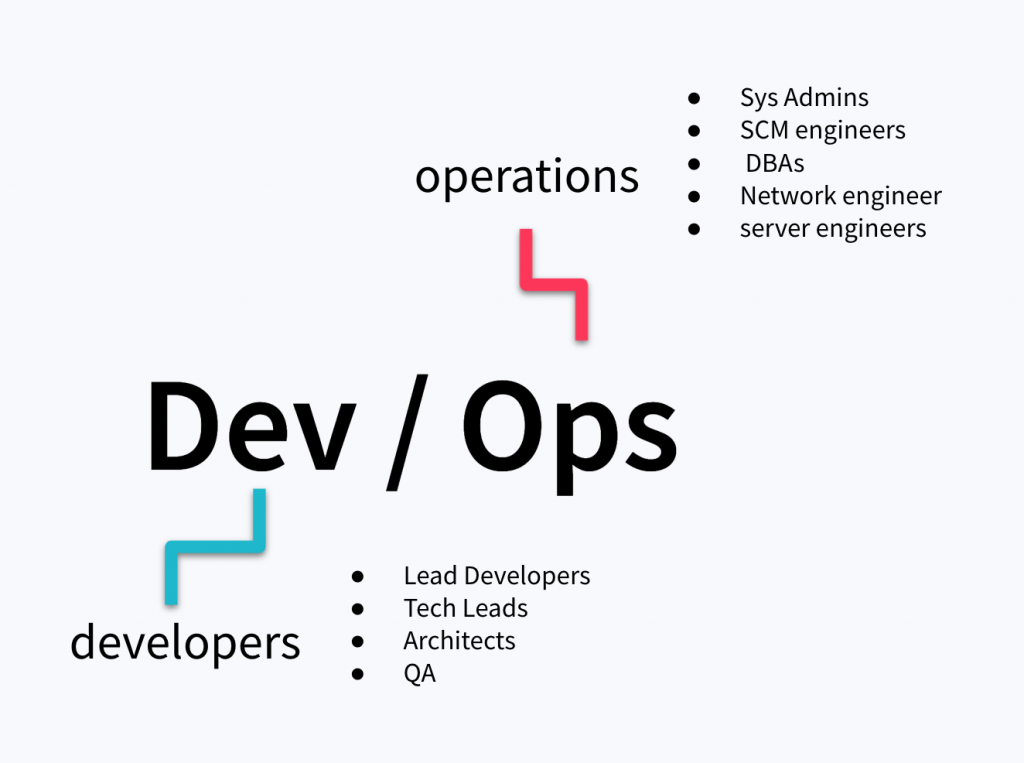
One takes care of the building process and the other takes care of maintenance. When we say developer team, we aren’t talking just about developers, we must include lead developers, tech leads, architects, and quality assurance engineers. And when we say operations team we are talking about system admins, software configuration management engineers, DBAs, network engineers, and server engineers. Everyone is responsible for deploying the application, maintaining the servers, databases, and monitoring the logs and traffic.
The DevOps movement started around 2006 in response to the culture of fear that the industry generated. The agile process was great at solving the issues between gathering requirements and building, but the software industry was still dysfunctional.
DevOps is a framework with a series of preconditions, activities, processes, and tools that are designed to solve and prevent some problems, such as production issues, rolling back incompatible changes, delayed releases, delays going live to market, and total team burnout. It also helps operations teams avoid having complex deployment sessions that are time-consuming because the more time between each update, the more those environments tend to diverge from each other. As a consequence, the discrepancies between the environments will impact the developers, making it more difficult for them to develop new features. To sum it up, these challenges make it harder to get something out to production.
What is this framework about and how can it help to solve some of these problems?
DevOps enables us to simultaneously improve organizational performance and the human condition.
-
End-to-end responsibility
Delivery is a team responsibility. The phrase “it works on my machine” is no longer valid. Developers and the operations team need to take ownership together. Both teams must collaborate from the beginning.
Example: Operations teams could prepare scripts to allow developer teams to work comfortably on their individual environments (automatic deployment scripts, automatic test data load, environment management scripts, for cleaning and cloning). If for any reason there are manual configurations that need to be made, the whole team will be responsible for documenting the changes needed, to make sure that a piece of code can be deployed to any given environment. The quality assurance team also has a primary role here as they will be the first ones to receive a finished piece of code, so it’s a great moment to test the scripts and correct any issues with the deployment activity.
-
Small increments over monolithic deliveries
It’s not easy for many new features to fit on a running server without any errors. Deliveries should be more frequent and with less “density,” meaning fewer features in each delivery. Ideally, we want just one small functional change to be delivered, so we can do it several times during a given period.
Example: Imagine you have an open-source free writing tool that crashes once in a while. You soon realize that you usually save your work when you finish a chapter (every two weeks) but this crash happens once a month, so when this happens you may lose almost two weeks of work in the worst case. You start saving frequently and eventually you end up saving after you finish a paragraph, so in the worst-case scenario, you would only lose one paragraph. This gives you a safer and systematic solution. The same approach applies to software. If for any reason you need to roll back, you only lose the last change and not the complete release.
-
Automate everything
We must reduce manual procedures as much as we can. This is where the operations team can help more, by defining configuration scripts, or data scripts that can be bound to the source code so when there is an environment that needs an update, these scripts will do all the preparation and post setup work. Sometimes this level of automation is not going to be possible, but the less manual configuration the better.
Example: Sometimes it happens that manual configuration is easier and faster than the scripts. Logging in to the environment and selecting an option on the settings menu is easier than creating a script, finding and writing the appropriate code, and finally, testing it. We are often tempted to find the easiest way. But what happens when this procedure needs to be done on every deployment (each server or each environment), after repeating the steps 10+ times, the script will seem the easiest way.
-
Run unit tests
Unit testing is the key to delivery reliability but developers tend to hate it. We sometimes don’t see the value of creating so many tests, especially that obvious one because it feels almost like losing time. But more often, unit testing is the part that we forget when we estimate a task.
Example: Imagine you only need to add a few lines of code and it will be done. You think it’s two story points for the estimate (story points are units of measure for expressing an estimate of the overall effort required to fully implement a product backlog item or any other piece of work.). Then when you write the code, you realize that you could unit test it, and when you dive into it, there are many tests that you need to write, so the task actually required more than two story points.
Continuous Integration (CI)
Continuous Integration (CI) is a development practice where developers integrate working code several times a day and each integration can be verified by automated tests. The word ‘integrate’ comes from the process of “adding the changes.” Working code is the code that passed all tests. If the code isn’t working it can’t be integrated. Also, each integration can be verified, this means that there is a history of these logs going on, this traceability aspect is very important since it can help to track issues and find the exact turning points where defects are introduced.
Continuous Integration goals
-
Easily detect integration bugs
Sometimes a test that works in our environment won’t work on another. This points out that there are differences between the environments that we need to address. Resolving the differences helps create an environment that is synchronized. It’s important to mention that the more updated tests you run, the stronger the application you build.
There are development practices like test-driven development that are based on this principle. They develop tests before the software is fully developed. Those practices are considered the most reliable way of programming and are the ones that achieve the highest development velocity. Despite the general belief that writing tests slow the developers down, it’s the other way around, because we lose more time trying to find the source of a defect than the time we lose writing a unit test.
-
Increase code coverage
Code coverage has been used as a metric that determines how reliable the unit tests are. It is based on a simple concept: if after a test run we have uncovered source code in areas of our application that we are not certain is correct, therefore, there could be unspotted defects. There are platforms like Salesforce that won’t let you deploy code that hasn’t reached a given amount of code coverage, helping ensure you introduce best practices
-
Develop faster and never ship broken code
Today, organizations adopting DevOps practices often deploy changes hundreds of times per day. In an age where competitive advantage requires fast time to market, organizations that are still driven by old-fashioned practices are doomed to fail. Two major points make a big impact on development velocity:
Hand-offs so the deployment can take place. Having to rely on other teams will only make the deployment slower because those teams won’t be prepared and will have to catch up with the task.
Debugging, when unexpected errors occur, and we don’t have a clue where they come from, fixing and debugging them can take many hours, even days. We know that having a unit test doesn’t guarantee a defect-free application, but it helps in identifying where the issues come from, and we can catch those issues at a very early stage, so fixing them is much faster and we will only promote working code.
-
Consistency in the build process
Using CI pipelines streamlines the process of product release, helping teams release high-quality code faster and more often and lets us rely on an automated framework that can repeat the process over and over again. This consistency is achieved by reducing manual procedures and hand-offs.
-
Increase confidence in the software
CI is the result of decades of experience and provides value by helping to deliver valuable systems to users faster. It helps to produce a higher quality code base with fewer defects. The severity and frequency of defects drop after adopting continuous integration. This assures that the production deployments will run a lot more smoothly by identifying incompatible aspects earlier, which is critical.
If you want to know more about DevOps and how become a certified DevOps engineer, we recommend AWS Certified DevOps Engineer – Professional. Also, we are looking for developers to grow our DevOps team, and check our available positions.



